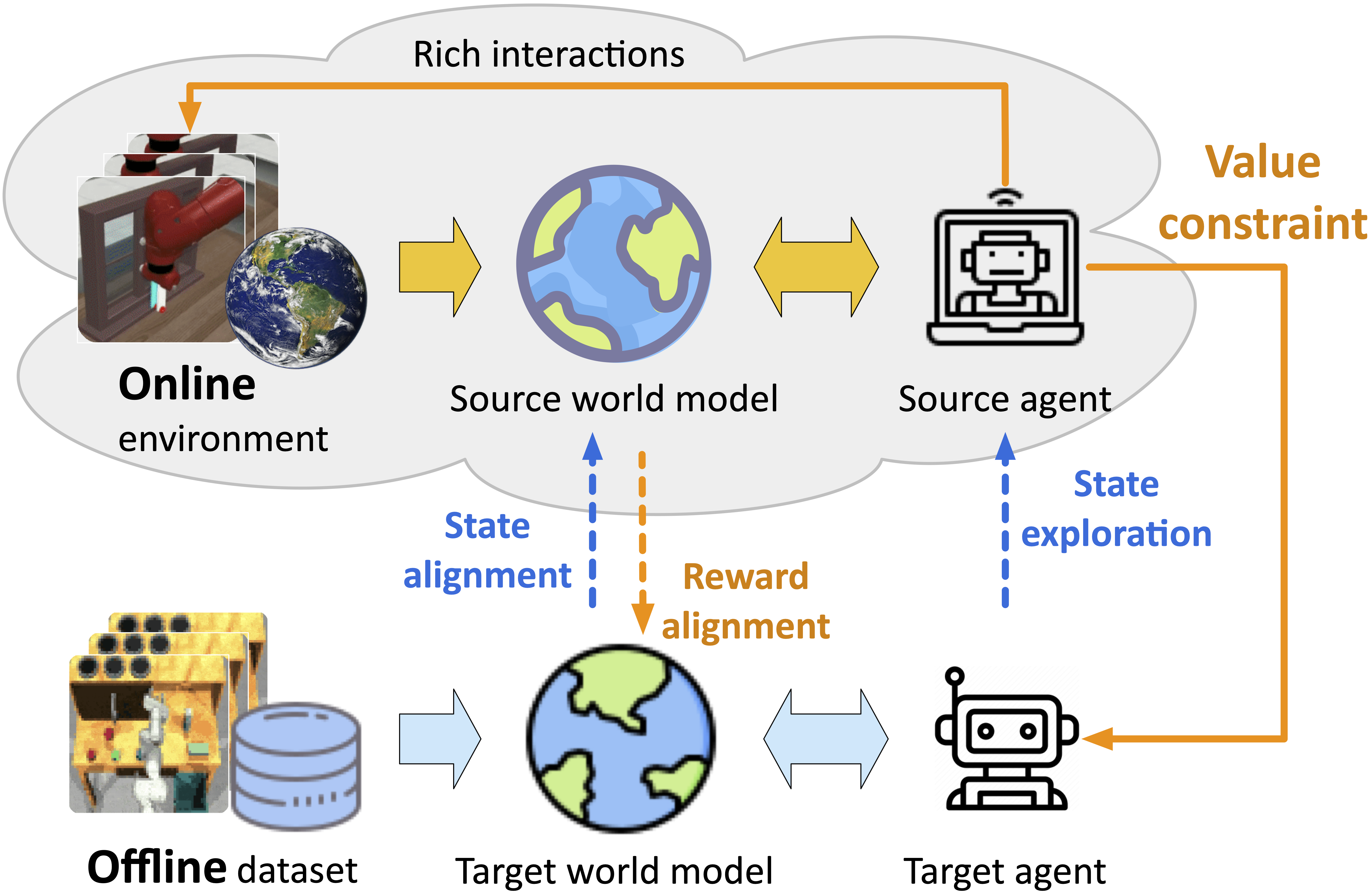
Training offline RL models using visual inputs poses two significant challenges, i.e., the overfitting problem in representation learning and the overestimation bias for expected future rewards. Recent work has attempted to alleviate the overestimation bias by encouraging conservative behaviors. This paper, in contrast, tries to build more flexible constraints for value estimation without impeding the exploration of potential advantages. The key idea is to leverage off-the-shelf RL simulators, which can be easily interacted with in an online manner, as the “test bed” for offline policies. To enable effective online-to-offline knowledge transfer, we introduce CoWorld, a model-based RL approach that mitigates cross-domain discrepancies in state and reward spaces. Experimental results demonstrate the effectiveness of CoWorld, outperforming existing RL approaches by large margins.
Showcases in Meta-World.
Showcases in DMC.
@inproceedings{wang2024making,
title={Making Offline RL Online: Collaborative World Models for Offline Visual Reinforcement Learning},
author={Qi Wang and Junming Yang and Yunbo Wang and Xin Jin and Wenjun Zeng and Xiaokang Yang},
booktitle={NeurIPS},
year={2024}
}
This website adapted from Nerfies template.