Training visual reinforcement learning agents in a high-dimensional open world presents significant challenges. While various model-based methods have improved sample efficiency by learning interactive world models, these agents tend to be "short-sighted", as they are typically trained on short snippets of imagined experiences. We argue that the primary challenge in open-world decision-making is improving the exploration efficiency across a vast state space, especially for tasks that demand consideration of long-horizon payoffs. In this paper, we present LS-Imgine, which extends the imagination horizon within a limited number of state transition steps, enabling the agent to explore behaviors that potentially lead to promising long-term feedback. The foundation of our approach is to build a long short-term world model. To achieve this, we simulate goal-conditioned jumpy state transitions and compute corresponding affordance maps by zooming in on specific areas within single images. This facilitates the integration of direct long-term values into behavior learning. Our method demonstrates significant improvements over state-of-the-art techniques in MineDojo.
Showcases of LS-Imagine in MineDojo.
We present the real interaction process of the trained LS-Imagine agent performing specified tasks in Minecraft.
The first row in each video represents the agent’s first-person perspective observation.
The second row, labeled "Affordance map", visualizes the relevance of different regions in the observation to the current task.
The third row, labeled "Alpha blend", overlays the affordance map with transparency over the first-person perspective observation, highlighting the regions that the agent focuses on.
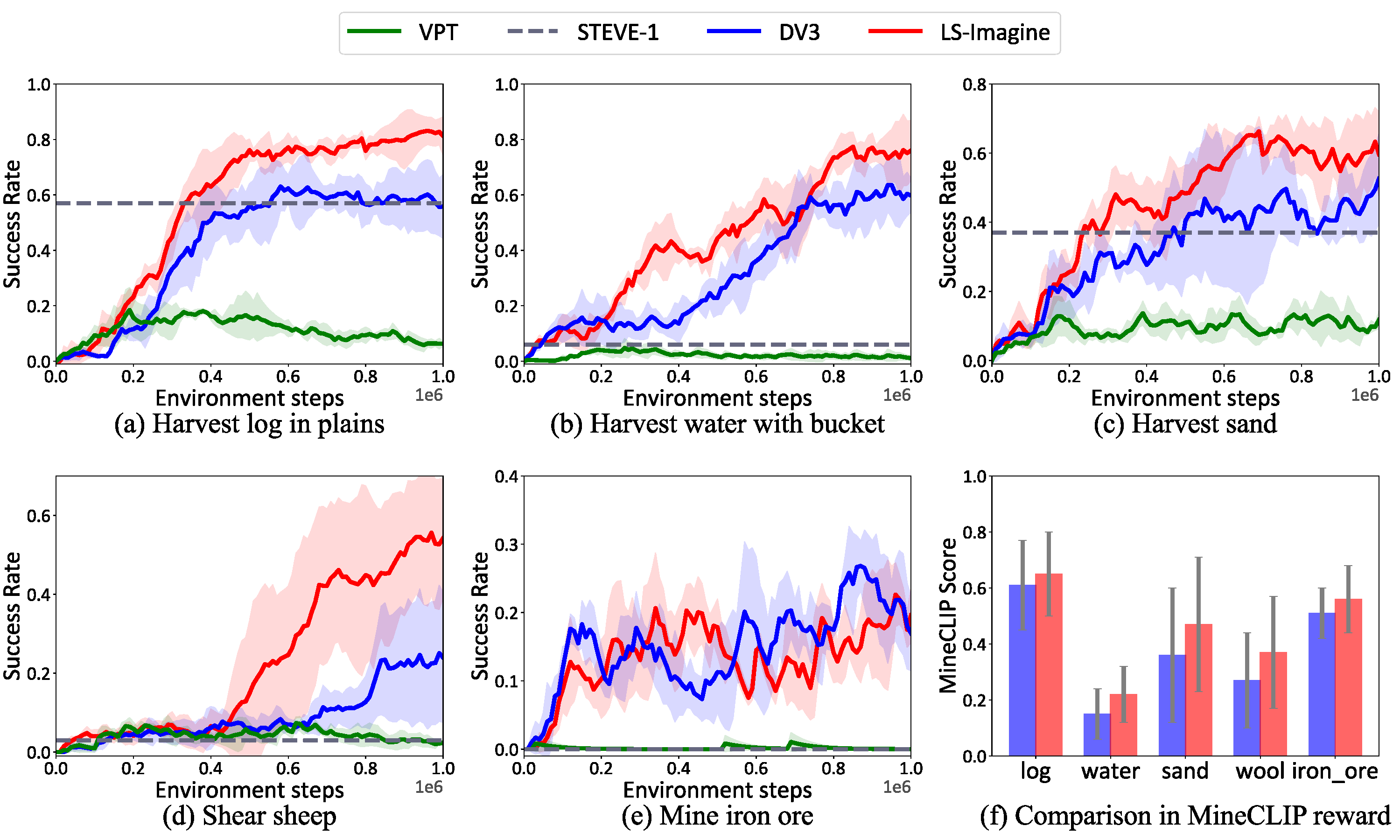
Performance comparison of LS-Imagine against existing approaches in MineDojo.
@inproceedings{li2025open,
title={Open-World Reinforcement Learning over Long Short-Term Imagination},
author={Jiajian Li and Qi Wang and Yunbo Wang and Xin Jin and Yang Li and Wenjun Zeng and Xiaokang Yang},
booktitle={ICLR},
year={2025}
}
This website adapted from Nerfies template.
 Open-World Reinforcement Learning over
Open-World Reinforcement Learning over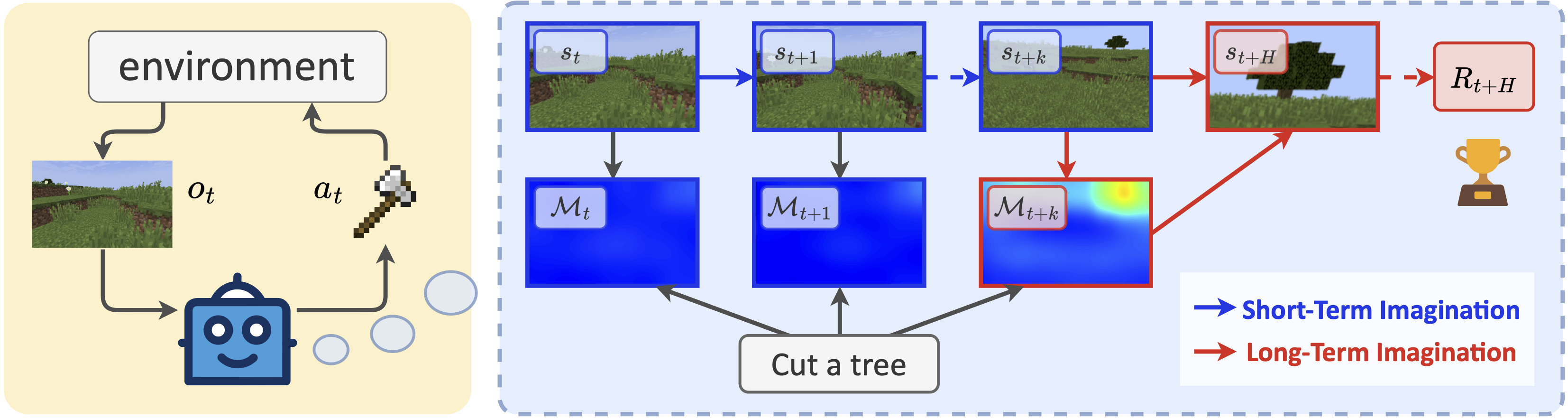
{kind=link}