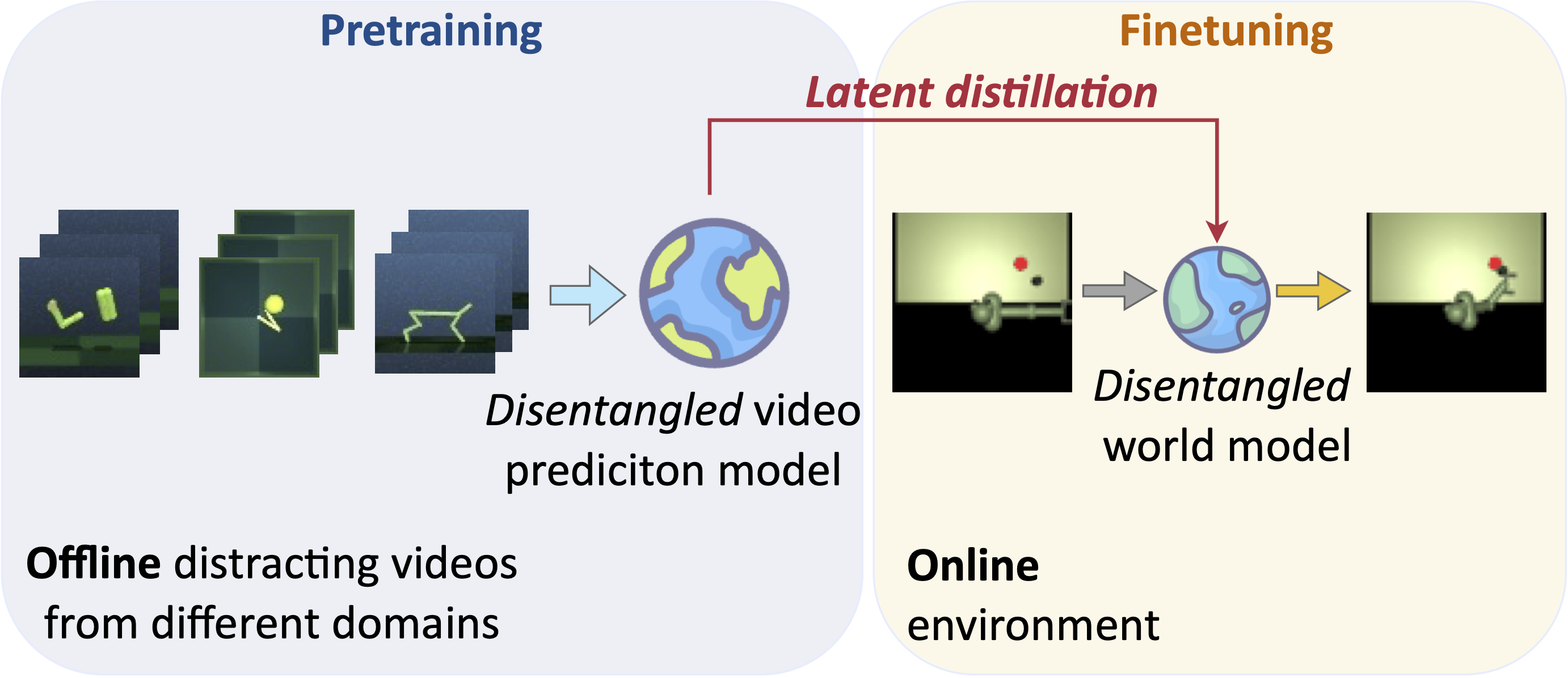
Training visual reinforcement learning (RL) in practical scenarios presents a significant challenge, i.e., RL agents suffer from low sample efficiency in environments with variations. While various approaches have attempted to alleviate this issue by disentangled representation learning, these methods usually start learning from scratch without prior knowledge of the world. This paper, in contrast, tries to learn and understand underlying semantic variations from distracting videos via offline-to-online latent distillation and flexible disentanglement constraints. To enable effective cross-domain semantic knowledge transfer, we introduce an interpretable model-based RL framework, dubbed Disentangled World Models (DisWM). Specifically, we pretrain the action-free video prediction model offline with disentanglement regularization to extract semantic knowledge from distracting videos. The disentanglement capability of the pretrained model is then transferred to the world model through latent distillation. For finetuning in the online environment, we exploit the knowledge from the pretrained model and introduce a disentanglement constraint to the world model. During the adaptation phase, the incorporation of actions and rewards from online environment interactions enriches the diversity of the data, which in turn strengthens the disentangled representation learning. Experimental results validate the superiority of our approach on various benchmarks.
Showcases in Drawerworld.
Showcases in DMC.
@inproceedings{wang2025disentangled,
title={Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning},
author={Qi Wang and Zhipeng Zhang and Baao Xie and Xin Jin and Yunbo Wang and Shiyu Wang and Liaomo Zheng and Xiaokang Yang and Wenjun Zeng},
booktitle={ICCV},
year={2025}
}This website adapted from Nerfies template.